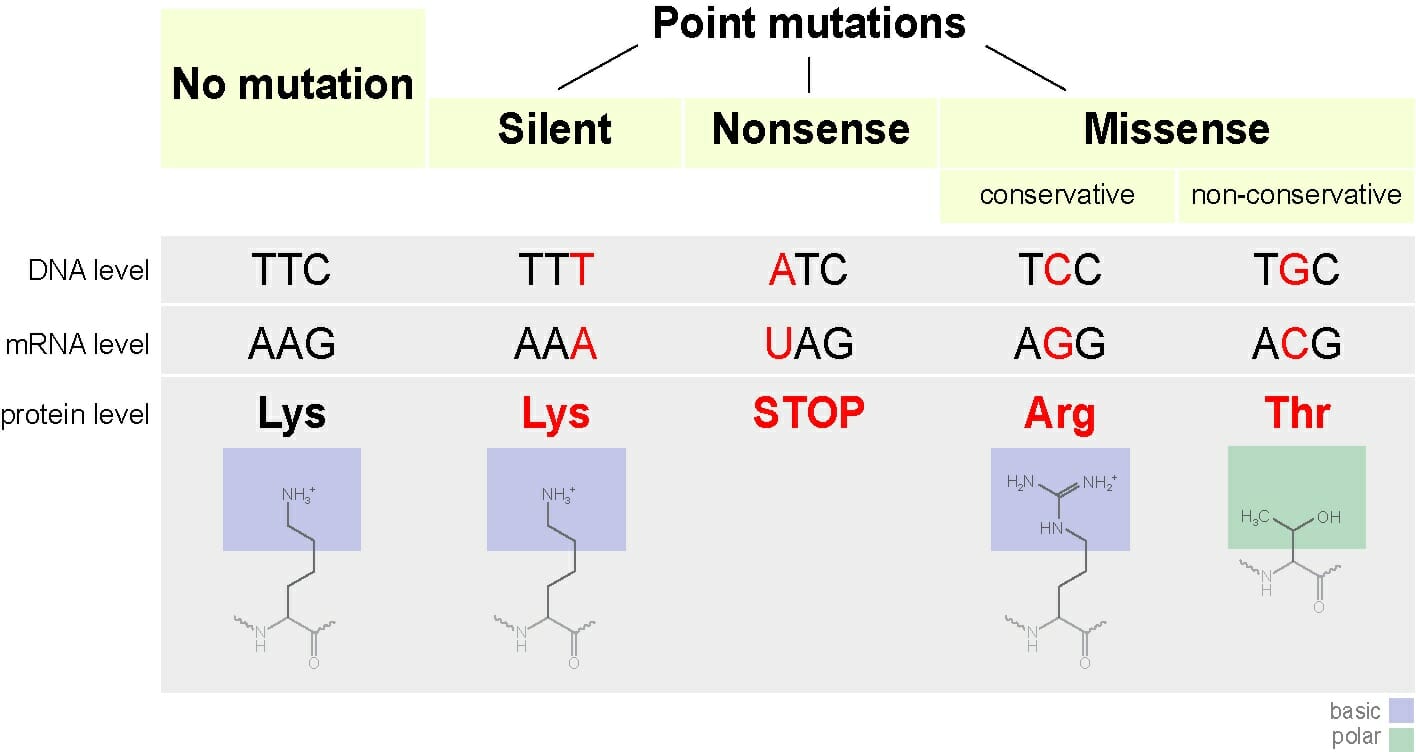
Virus Definition
A virus is a chain of nucleic acids (DNA or RNA) which lives in a host cell, uses parts of the cellular machinery to reproduce, and releases the replicated nucleic acid chains to infect more cells. A virus is often housed in a protein coat or protein envelope, a protective covering which allows the virus to survive between hosts.
Virus Structure
A virus can take on a variety of different structures. The smallest virus is only 17 nanometers, barely longer than an average sized protein. The largest virus is nearly a thousand times that size, at 1,500 nanometers. This is really small. A human hair is approximately 20,000 nanometers across. This means that most virus particles are well beyond the capability of a normal light microscope. Below is a scanning electron microscope (SEM) image of the Ebola virus.
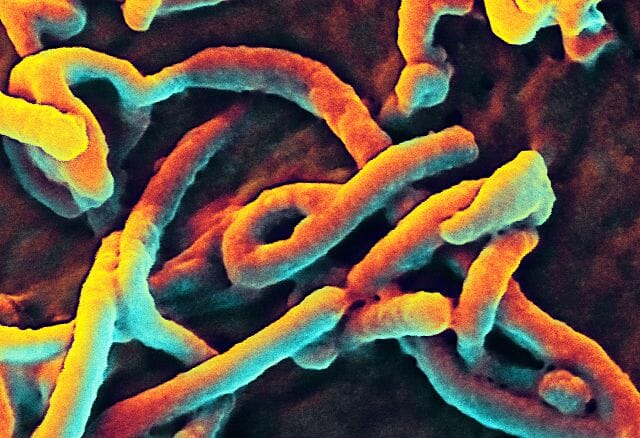
Ebola Virus
Here, you can only see the protein coat of the Ebola virus. Each virus looks like a little bent worm. However, these are not cells. Inside of the protein coat is a carefully folded RNA molecule, which contains the information necessary to replicate the protein coat, the RNA molecule, and the components necessary to hijack a cell’s natural processes to complete these tasks.
The exact structure of a virus is dependent upon which species serves as its host. A virus which replicates in mammalian cells will have a protein coat which enables it to attach to and infiltrate mammalian cells. The shape, structure, and function of these proteins changes depending on the species of virus. A typical virus can be seen below.
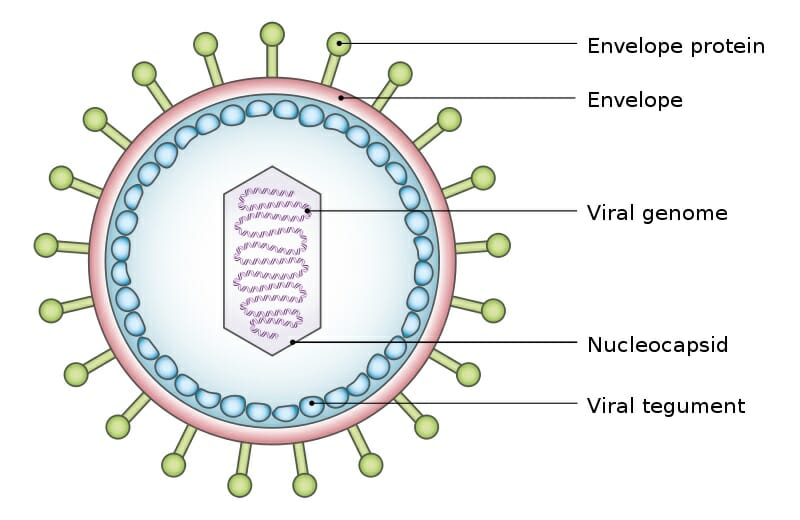
Viral Tegument
The above virus shows the typical structure a virus takes, a viral genome surrounded by a shield of proteins. The various envelope proteins will enable the virus to interact with the host cell it finds. Part of the protein coat will then open, puncture through the cell membrane, and deposit the viral genome within the cell. The protein coat can then be discarded, as the viral genome will now replicate within the host cell. The replicated virus molecules will be packaged within their own protein coats, and be released into the environment to find another host. While many virus particles take a simple shape like the one above, some are much more complicated.
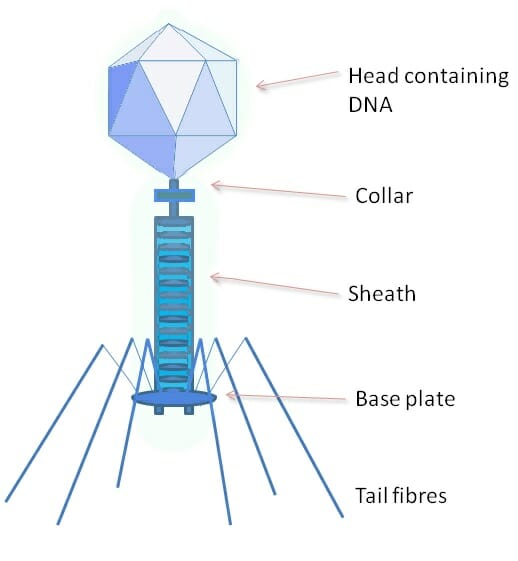
Phage
The above image shows a phage, a type of virus which specializes on bacterial cells. The protein coat of a phage is much more complex, and has a variety of specialized parts. The head portion contains the viral genome. The collar, sheath, base plate, and tail fibers are part of an intricate system to attach to and inject the genome into a bacterial cell. The tail fibers grasp the bacterial cell, pulling the base plate up to the cell wall or membrane. The sheath and collar compress, puncture the cell, and deposit the DNA into the bacterial cell.
Some virus molecules have no protein coat whatsoever, or have never been identified making on. In some plant virus species, the virus is passed from cell to cell within the plant. When seeds are created within the plant, the virus spreads to the seeds. In this way the virus can live within cells its entire existence, and never need a protein coat to protect it in the environment. Other virus molecules have even larger and more complex protein coats, and specialize on various hosts.
Is a Virus Living?
This is a complicated question. A cell is considered to be living because it contains all the necessary components to replicate its DNA, grow, and divide into new cells. This is the process all life takes, where it is a single-celled organism or a multi-cellular organism. Some people do not consider a virus living because a virus does not contain all of the mechanisms necessary to replicate itself. They would say that a virus, without a host cell, cannot replicate on its own and is therefore not alive.
Yet, by the definition of life laid out before, it seems that when a virus is inside of a host cell it does have all the machinery it needs to survive. The protein coat it exists in outside of a cell is the equivalent of a bacterial spore, a small capsule bacteria form around themselves to survive harsh conditions. Scientists who support a virus being a living organisms note the similarity between a virus in a protein coat and a bacterial spore. Neither organism is active within their protective coat, they only become active when they reach favorable conditions.
In fact, the only reason a virus affects us at all is because it becomes active within our cells. Further, a virus tends to evolve with its host. Most dangerous viruses have just recently jumped to a new species. The biochemistry they evolved to live within the other species is not compatible with the new species, and cell damage and death occur. This causes a number of reactions, depending on which cells were infected. The HIV virus, for instance, attacks immune cells exclusively. This leads to a total loss of immune function in patients. With the virus causing the common cold, the virus attacks respiratory cells and damages them as it does its work.
Yet, not all virus infections will be detrimental to the host. A virus that kills the host will be less successful over time, compared to a virus which doesn’t harm the host. A healthy host increases the number of virus molecules released into the environment, which is the ultimate goal of the virus. In fact, some virus particles may actually benefit the host. A good example is a form of herpes virus, found in mice. This virus, while it is infecting a mouse, provides the mouse with a good defense against the bacteria which carry the plague. While the mechanism is not clear, the virus somehow prevents the bacteria from taking hold in the mouse’s system.
When viewed in this light, it is easy to see how a virus is very similar to a bacteria. The bacteria creates and maintains the tools needed to reproduce DNA, where the virus steals them. This is the only real difference between a virus and a bacteria. Because of this, many scientists consider a virus a living organism. Scientists who study viruses, virologists, note that virus particles (alive or not) have been evolving with life probably as long as the first cells were present. Because of this, there is a virus which specializes on almost every single species on the planet.
Virus Classification
Scientists classify viruses based on how they replicate their genome. Some virus genomes are made of RNA, others are made of DNA. Some viruses use a single strand, others use a double strand. The complexities involved in replicating and packaging these different molecules places viruses into seven different categories.
Class I virus genomes are made of double stranded DNA, the same as the human genome. This makes it easy for these virus molecules to use the cell’s natural machinery to produce proteins from the virus DNA. However, in order for DNA polymerase (the molecule which copies DNA) to be active the cell must be dividing. Some Class I virus molecules include sections of DNA which make the cell actively start dividing. These virus molecules can lead to cancer. Human papilloma virus is a sexually-transmitted Class I virus, and can cause cervical cancer.
A Class II virus contains only a single strand of DNA. Before it can be read by the host’s DNA polymerase enzymes, it must be converted to double stranded DNA. It does this by hijacking the host cell’s histones (DNA proteins) and DNA polymerase. Instead of waiting for the cell to divide or forcing it to, Class II virus DNA contains coding for a protein called Rep. This replication enzyme replicates the original single-stranded virus genome. Other proteins are created from the DNA and used to create protein coats with the cellular machinery. The single-stranded DNA is then packaged into these protein coats, and new virus packages are created.
Class III virus genomes are created from double-stranded RNA. While this is unusual, these virus packages come with their own protein, RNA polymerase. This protein can create messenger RNA (mRNA) from the double-stranded virus RNA. The virus RNA therefore stays within the virus capsule, and only the mRNA enters the cytoplasm of the host. Here, the mRNA is converted into proteins, some of which include more RNA polymerase. This RNA polymerase creates a new double-stranded RNA, which is encapsulated by the proteins and released from the cell.
Class IV viruses are single-stranded RNA, almost identical to mRNA produced by the host cell. With these viruses the entire protein coat is engulfed by an uninfected host cell. The small RNA genome escapes the protein coat, and makes its way into the cytoplasm. This one mRNA-like strand codes for a large polyprotein, which will be created by the hosts ribosomes. The polyprotein naturally breaks into different parts. Some create protein coats, while others read and replicate the original strand of viral RNA. The virus continues to replicate and create new, fully packed virus particles. When the cell is completely full, it ruptures and releases the virus particles into the blood or environment. Up to 10,000 virus particles can be release from a single cell.
The virus genomes in Class V are also single-stranded RNA. However, they run in the opposite direction from normal mRNA. Therefore, the cell’s machinery cannot read them directly. These virus molecules contain a RNA polymerase molecule which can read in reverse. These virus molecules have large capsules, surrounded by cell membrane and proteins. When the virus approaches a cell, its membrane proteins bind with the cell, and it is drawn into the cytoplasm. Here, it breaks apart, releasing the backwards viral RNA and associated proteins. These small complexes produce regular mRNA, which creates new virus complexes. These unfinished complexes move to the cell surface, where they line the cell membrane with proteins they create. When they are finished, they wrap themselves in this membrane, and tear away from the cell.
Class VI virus genomes are the same as Class V, but they use a different method to replicate. Class VI virus particles are known as retroviruses. Instead of creating mRNA from the viral RNA, these virus molecules work with a different protein. Known as reverse transcriptase, this enzyme is able to create DNA from the virus RNA. In doing so, the viral RNA is converted to double-stranded DNA. This DNA then produces new virus. The DNA can incorporate with the host DNA, and in doing so become endogenized. This means that the DNA will remain in the cell as long as the cell lives. If the cell is found in a germ line, such as a sperm or egg, the virus will permanently become a part of the host’s genome. It is estimated that 5-8% of the human genome is left over retrovirus DNA.
The final class, Class VII, includes the pararetroviruses. Similar to Class VI, these virus genomes use reverse transcriptase. However, these virus genomes are package as DNA, not RNA. These viruses insert themselves directly into the host genome, which begins transposing the viral DNA into RNA. Most of this RNA will be mRNA, used to create a polyprotein. Part of the polyprotein is reverse transcriptase. This reverse transcriptase works on pieces of RNA known as pregenome. It reads these RNA molecules and produces the original virus DNA. This is then packaged into viral protein coats. Class VII viruses are often found in plants, and can travel between cells using the plasmodesmata, or they can be carried by herbivorous insects feeding on the plants. Aphids carry many plant diseases, as their proboscis pierces plant cell walls and they drink the cytoplasm.
Examples of a Virus
Polio Virus
The Polio virus, which crippled President Franklin Roosevelt, is a Class III virus. This double-stranded RNA virus encodes for 12 proteins. Like other Class III virus genomes, it reproduces by releasing mRNA strands into the cytosol of host cells, which code for new virus molecules. Interestingly, the polio virus was not deadly, until people started treating their water. Before chlorinated water, polio survived in most water sources. Thus, most infants were exposed to polio right off the bat.
In infants, there are usually no symptoms of polio, and the immune system responds to the virus. However, after chlorinated water was established, most children did not experience polio. However, the disease was not eradicated. Many people were exposed in adulthood to pockets of polio which still persisted. These people suffered greatly from the disease, as the immune system did not react quickly enough to it. Like FDR, they were usually permanently crippled from the effects of the virus on bone health. Luckily the vaccine for polio, one of the first ever created, is easily made from killing live polio virus with heat. The dead protein coats allow the body to develop an immunity to the virus, without cells being infected.
Rabies Virus
The rabies virus is a Class V virus, with a bullet-shaped protein coat. This virus is made of linear, single-stranded RNA. The rabies virus genome codes for five proteins, from 12,000 nucleotides. Interestingly, the symptoms of rabies in many animals include increased aggression. This trait, caused by where the virus attacks and the damage it does, causes animals to bite other animals more often than they normally would. The assembled rabies virus particles accumulate in the saliva. Thus, when an infected animal bites another one the virus is passed to the new animal.
Rabies virus is almost always fatal in humans, if not treated immediately. Yearly, there are nearly 15 million post-exposure vaccinations given for rabies. The vaccine essentially loads the body with the dead virus, allowing a large immune response against the virus. This can stop the virus before it gets established in the system. If this happens, there is little chance of recovery. Dogs are commonly vaccinated pre-exposure, which provides a general protection to their owners on the chance they are bitten by an animal infected with the virus.
Quiz
1. Which of the following classes of virus genome can be reproduced directly by cellular machinery?
A. Class I
B. Class III
C. Class VI
Answer to Question #1
A is correct. Class I virus genomes are made of DNA, and double-stranded at that. This means the viral genome is ready to be copied into mRNA, without intermediate steps found in the other classes of virus.
2. Human Rhinovirus A causes the common cold. The genome of rhinovirus is a single-stranded RNA, similar to mRNAs produced by the host cell. Which class does rhinovirus belong to?
A. Class VII
B. Class II
C. Class IV
Answer to Question #2
C is correct. Class IV includes all of the mRNA-like virus genomes. These viruses can be translated directly by the host’s ribosomes into proteins, skipping the steps other viruses take.
3. Your friend claims that viruses are the same as allergies, as both cause his nose to run. Which of the following will convince your friend otherwise?
A. Only viruses cause an immune reaction
B. A virus not only causes a reaction, it reproduces within your cells
C. Why argue? Your friend is right.
Answer to Question #3
B is correct. Both substances do cause an immune reaction. The immune system is responsible for recognizing self vs other. The difference is that allergens, such as pollen and dust, don’t self-replicate within your cells after taking them over.
References
- Nelson, D. L., & Cox, M. M. (2008). Principles of Biochemistry. New York: W.H. Freeman and Company.
- Roossinck, M. J. (2016). Virus. Princeton: Princeton University Press.
- Widmaier, E. P., Raff, H., & Strang, K. T. (2008). Vander’s Human Physiology: The Mechanisms of Body Function (11th ed.). Boston: McGraw-Hill Higher Education.
Virus